Our journey of sharing GPU in Kubernetes
GPU’s popularity has been increasing for last decade with increasing usage in ML and other AI applications. We have seen a lot of application using GPUs as key computation component for processing. We struck with one such use-case of ASR(Automated Speech Recognition) and TTS(Text to Speech).
Context
Team built an amazing service to provide ASR and TTS for indic languages. GPUs were considered to have better performance. Kubernetes chosen to keep things simple and scalable at various levels. Everything was smooth until we got to know that we have to share GPUs and kubernetes does not have native support for GPUs. K8s official documentation says
Kubernetes includes experimental support for managing AMD and NVIDIA GPUs (graphical processing units) across several nodes.
Our services were using libraries like pytorch which were using NVIDIA’s CUDA for GPU computations.
Nvidia CUDA (Compute Unified Device Architecture)
Provides abstraction and high level language support on a variety of Nvidia GPUs.
- Native CUDA programming can be done in C or C++
- Use a wrapper library like python, Java
More on it CUDA documentation.
Why Share GPUs
- GPUs are expensive.
- Better utilization of GPU cycles and memory
- One model instance may not consume it all.
- Availability of best fit GPUs for your workload.
We always want to get most value out of any resource that we use. Our benchmarking showed the scope to do more on one single GPU.
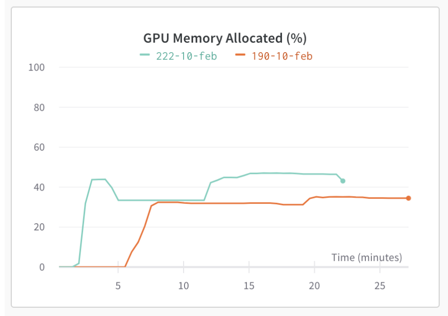
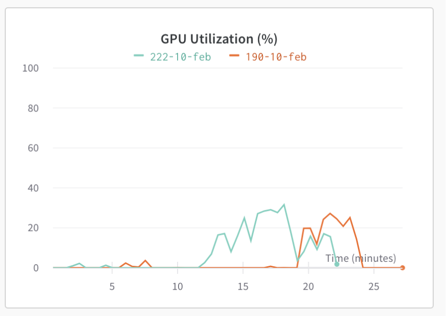
*Peeks in the graphs represent load. We did these runs to benchmark our ASR model service. Here, one ASR model was running on an Nvidia T4 GPU which has 16 GB memory. With our increase in load utilization increases but saturates at a level and did not increase with increase in load (load means increase in number of concurrent request).
These load runs made it clear that deploying one instance of the service (one model running in a service) per GPU wasn’t the best use of it. We can load more models on to one GPU and get better results. We also have to mindful of that fact that current generations of GPUs are not designed for parallel workloads. So benchmarking plays important role in understanding the impact.
GPU with Kubernetes
Kubernetes has no internal support for GPU resource scheduling and isolation. Instead, it is implemented by third-party through the device plugin and scheduler extension.
As per k8s documentation (https://kubernetes.io/docs/tasks/manage-gpus/scheduling-gpus)
Kubernetes includes experimental support for managing AMD and NVIDIA GPUs across several nodes. Containers (and Pods) do not share GPUs. There’s no overcommitting of GPUs. Each container can request one or more GPUs. It is not possible to request a fraction of a GPU.
What you can do
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU, Your pod will see one GPU only.
This will only take care of scheduling your workload to an available GPU. It will be able to restrict utilization, memory etc. which you would usually find with other resources like memory, CPU. This feature will restrict the GPU visibility to your pod, it will only see defined number of GPUs in your pod. No other workload will be allowed to schedule on that instance with those GPUs assigned.
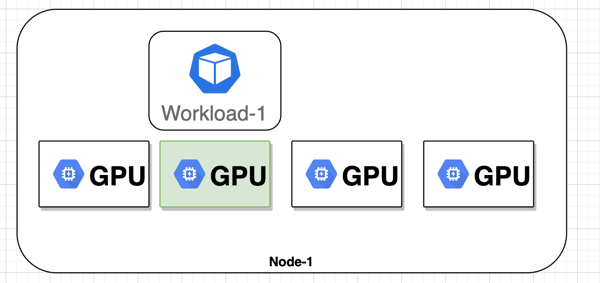
You cannot do this
resources:
limits:
nvidia.com/gpu: 0.5 # cannot request fractions.
Trick
You can set nvidia.com/gpu value to 0 and still workload will be able to see all the GPUs available on the instance. It will also not block the GPU on kubernetes to more workloads can be scheduled on that node.
resources:
limits:
nvidia.com/gpu: 0 # This will work fine and will not block your GPU for other workloads.
Ways to achieve GPU sharing in kubernetes
There are multiple ways to share a GPU instance with multiple processes like we do with CPU.
Hardware level partitioning
This was our first level of option. NVIDIA provides an option of creating MULTI-INSTANCE GPU at hardware level. One single physical GPU can be mapped to machine as upto seven GPUs. This feature is limited to specific NVIDIA GPUs and need a cluster/machine level changes to support.
Virtual GPUs
This is similar to what we do we CPU but not as cool. AWS has created device plugin to support creation of VGPUs (Virtual GPU) https://github.com/awslabs/aws-virtual-gpu-device-plugin.
- We can allocate 10 virtual GPUs for each physical GPU.
- We can run more than one pod on a physical GPU.
- We can exploit multi-process service for better performance.
If you have large GPUs, you can do MIG and on top of that use device plugin.
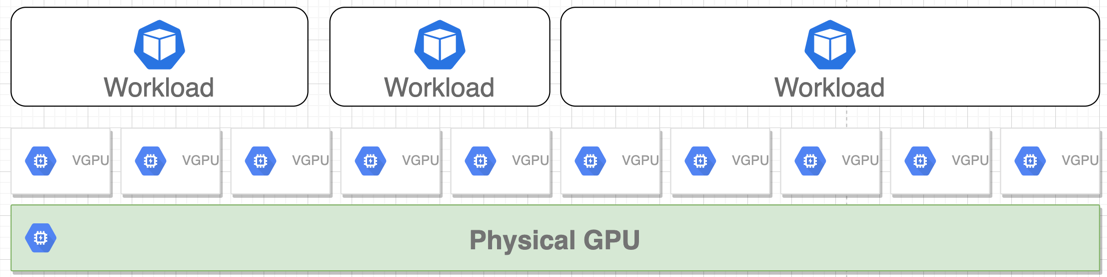
This will require you to replace your exiting GPU driver with AWS virtual GPU driver.
Limitations: Plugin does provide any constraints over resource consumption. Process has to put limits itself.
Even in EKS this does not come out of the box as of April-2022. You have to install it on your cluster.
Custom implementations
MIG and Virtual GPU both these options require you to provision your hardware or cluster with custom drivers. In case, you do not have access to such level only choice that remain with us is GPU Sharing without Kubernetes. This can be done in multiple ways.
Writing custom code
In case you have multiple GPUs attached to one single machine. CUDA will by default load data to 0th device. You can change that by creating a device object and passing this device object at all the places. Another challenge is deciding which GPU to use.
Challenges
- By default, CUDA uses 0th device.
- CUDA does not provide support to get memory usage of a GPU in any programmatic way.
Sample nvidia-smi output
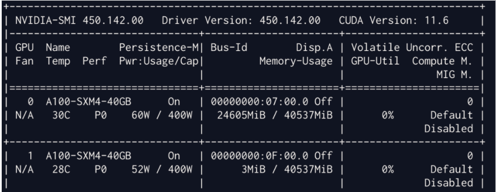
Solution
- Change your code to load models and data on specific device.
- Parse output of nvidia-smi to see memory consumption of a GPU.
Tip for Python Users GPUtil is a package to select GPU based on your criteria.
GPUtil.getAvailable(order='memory', limit=1, maxLoad=0.8, maxMemory=0.75,excludeID=excluded_gpus)
Reference CUDA python library
Using CUDA_VISIBLE_DEVICES
CUDA provides a range of environment variable which can be used to control the visibility of GPU devices at process level. CUDA_VISIBLE_DEVICES is one such variable. When you are starting a process you can set an environment variable CUDA_VISIBLE_DEVICES with one or list of GPU ids and that process will only see those GPUs as available devices. As this is done at process leve, k8s does not know about this hence you can run multiple workload on same GPU device with your judgement of memory and utilization.
Expose 2nd GPU
CUDA_VISIBLE_DEVICES: "1"

Expose 2nd and 3rd GPU
CUDA_VISIBLE_DEVICES: "1,2"

Summary
GPU sharing is still an experimental feature in kubernetes. There are efforts going on to make it available. Till then, we have to live with workarounds like these to make it work. It requires a bit of planning upfront to know which workload will go where and what GPU instance will be used by them.
References: